Part 02: Building a scalable Jenkins server on a Kubernetes Cluster
System Implementation


Table of contents
Introduction
In part 1, we introduced the system architecture as well as its importance to the business. This part will discuss in-depth the infrastructure implementation using Terraform (IaC). We will dig into the coding of different parts of the system (VPC, Subnets, Helm Releases, etc.). Not to mention the configuration of our star, Jenkins Server, will be also discussed.
System Implementation
The implementation is divided into three main parts:
- AWS infrastructure provisioning
- Jenkins configuration
- Monitoring tools configuration
AWS Cloud Components
In this section, we will show the implementation details for the AWS components. In addition, a simple explanation of the code will be added.
AWS VPC
resource "aws_vpc" "seitech-vpc" {
cidr_block = var.vpc_cidr_block
enable_dns_hostnames = true
enable_dns_support = true
tags = {
Name = "${var.cluster_name}-vpc"
}
}
The block shows that we will use the resource aws_vpc from the Terraform AWS provider. seitech-vpc is just a name for referencing this object in other Terraform files and code.
To build a VPC, you just need to define a CIDR block (the address space). This CIDR block is defined in the attribute cidr_block and is assigned from the variables.
enable_dns_support and enable_dns_hostnames enable private access for Amazon EKS cluster's Kubernetes API server endpoint and limit, or completely disable, public access from the internet.
tags are just key and value pairs that define the assigned tags to the VPC. Here we use string interpolation to assign a tag name for the AWS VPC. Again, note the use of the cluster_name variable.
The vpc_cidr_block variable definition may be like:
variable "vpc_cidr_block" {
type = string
default = "10.0.0.0/16"
description = "VPC CIDR Block"
}
This variable may be assigned to any other valid CIDR block through the tfvars file or Terraform CLI. But the default value is used otherwise.
AWS Internet Gateway
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.seitech-vpc.id
tags = {
Name = "${var.cluster_name}-gw"
}
}
The same code as VPC. The difference is that to build an Internet Gateway we need to assign the vpc_id. You may note how we referenced the vpc_id from the VPC object recently defined.
AWS Public and Private Subnet
Public Subnet
We have discussed in part 1 the overall architecture of the system. This architecture depicts the usage of two public subnets in different availability zones. The code below shows the basic structure of one of them and the other is the same except for changing the availability zone.
resource "aws_subnet" "public-seitech-subnet1" {
vpc_id = aws_vpc.seitech-vpc.id
cidr_block = var.public_subnet1_cidr_block
availability_zone = var.public_subnet1_az
map_public_ip_on_launch = true
tags = {
"Name" = "${var.cluster_name}-public-subnet1"
"kubernetes.io/role/elb" = "1"
"kubernetes.io/cluster/${var.cluster_name}" = "owned"
}
}
A weird thing to notice is the tags. The first tag is familiar to us as shown before. But the subsequent tags are not the case. These tags are required by the AWS EKS implementation reference in order to enable the EKS cluster of managing the nodes in these subnets.
map_public_ip_on_launch is used to automatically assign public IPs for services deployed inside the private subnet.
Private Subnet
resource "aws_subnet" "private-seitech-subnet1" {
vpc_id = aws_vpc.seitech-vpc.id
cidr_block = var.private_subnet1_cidr_block
availability_zone = var.public_subnet1_az
tags = {
"Name" = "${var.cluster_name}-private-subnet1"
"kubernetes.io/role/internal-elb" = "1"
"kubernetes.io/cluster/${var.cluster_name}" = "owned"
}
}
The private subnet captures the same structure as before. Except for a small change in the second tag. This tag is also defined by AWS EKS documentation as a flag to the cluster to manage the private (not public) worker nodes.
NAT Gateways
A NAT gateway is a Network Address Translation (NAT) service. We use a NAT gateway so that instances in a private subnet can connect to services outside the VPC but external services cannot initiate a connection with those instances.
To create a NAT gateway we need to have the following attributes:
- allocation_id: the elastic IP to associate with the NAT gateway.
- subnet_id: the subnet id where the NAT resides.
The following code shows that we can simply create an Elastic IP by specifying the attribute vpc to be true.
resource "aws_eip" "nat_eip1" {
vpc = true
tags = {
Name = "nat-eip1"
}
}
resource "aws_nat_gateway" "nat1" {
allocation_id = aws_eip.nat_eip1.id
subnet_id = aws_subnet.public-seitech-subnet1.id
tags = {
Name = "${var.cluster_name}-NatGatewayAZ1"
}
depends_on = [aws_eip.nat_eip1, aws_subnet.public-seitech-subnet1]
}
The NAT gateway attributes are assigned as needed by referencing their objects. One thing to note is the depends_on attribute. This is a terraform intrinsic attribute that explicitly defines the dependency between the needed objects to create. It is assigned to an array of objects (EIP and Subnet) to ensure that any errors due to dependence are resolved.
Another EIP and NAT Gateway are defined for the other public subnet. The naming is the difference only.
Route Tables
The final component in the networking infrastructure is the Route Table. We will define only one public route table to the public internet that will be associated with both the public subnets.
resource "aws_route_table" "public" {
vpc_id = aws_vpc.seitech-vpc.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
tags = {
Name = "Public Subnets"
Network = "Public"
}
depends_on = [
aws_vpc.seitech-vpc
]
}
The code shows that we open all the traffic to the public internet ingress using the Internet Gateway defined before.
The next code is the private route table for one of the private subnets. It opens the egress traffic to the internet through the NAT Gateway.
resource "aws_route_table" "private1" {
vpc_id = aws_vpc.seitech-vpc.id
route {
cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.nat1.id
}
tags = {
Name = "Private Subnet AZ1"
Network = "Private1"
}
depends_on = [
aws_nat_gateway.nat1,
aws_vpc.seitech-vpc
]
}
We will have another route table for the other private subnet. Again, change only the subnet id and the tags.
Till now we have created all the networking infrastructure and glued the components together, except for gluing the route table and the subnets.
resource "aws_route_table_association" "private-us-east-1a" {
subnet_id = aws_subnet.private-seitech-subnet1.id
route_table_id = aws_route_table.private1.id
}
resource "aws_route_table_association" "private-us-east-1b" {
subnet_id = aws_subnet.private-seitech-subnet2.id
route_table_id = aws_route_table.private2.id
}
resource "aws_route_table_association" "public-us-east-1a" {
subnet_id = aws_subnet.public-seitech-subnet1.id
route_table_id = aws_route_table.public.id
}
resource "aws_route_table_association" "public-us-east-1b" {
subnet_id = aws_subnet.public-seitech-subnet2.id
route_table_id = aws_route_table.public.id
}
The last snippet of code shows the association configuration of the public route table to the public subnet and the private route table to the corresponding subnets.
AWS EKS
Yet another important component of the system is the Kubernetes cluster. This cluster will be provisioned using the AWS EKS service. Provisioning an EKS is much simpler than the last-mentioned components.
resource "aws_eks_cluster" "seitech-cluster" {
name = var.cluster_name
role_arn = aws_iam_role.seitech-cluster-role.arn
vpc_config {
subnet_ids = [
aws_subnet.private-seitech-subnet1.id,
aws_subnet.private-seitech-subnet2.id,
aws_subnet.public-seitech-subnet1.id,
aws_subnet.public-seitech-subnet2.id
]
}
depends_on = [aws_iam_role_policy_attachment.demo-AmazonEKSClusterPolicy]
}
The last code shows that we need only a name for the cluster, role, and subnets. We have the name and the subnet ids but we don't have the role arn.
This role arn will be created using the following code:
resource "aws_iam_role" "seitech-cluster-role" {
name = "seitech-cluster-role"
assume_role_policy = <<POLICY
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "eks.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
POLICY
}
resource "aws_iam_role_policy_attachment" "demo-AmazonEKSClusterPolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
role = aws_iam_role.seitech-cluster-role.name
}
There is no much to discuss regarding this block. Just define roles and policies as in the AWS documentation.
IAM OIDC
To manage permissions for the applications that we deploy in Kubernetes. We can either attach policies to Kubernetes nodes directly. In that case, every pod will get the same access to AWS resources. Or we can create OpenID connect provider, which will allow granting IAM permissions based on the service account used by the pod.
data "tls_certificate" "eks" {
url = aws_eks_cluster.seitech-cluster.identity[0].oidc[0].issuer
}
resource "aws_iam_openid_connect_provider" "eks" {
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = [data.tls_certificate.eks.certificates[0].sha1_fingerprint]
url = aws_eks_cluster.seitech-cluster.identity[0].oidc[0].issuer
}
EKS Autoscaler
We will be using OpenID connect provider to create an IAM role and bind it with the auto scaler. Let's create an IAM policy and role first. It's similar to the previous one, but autoscaler will be deployed in the kube-system namespace.
data "aws_iam_policy_document" "eks_cluster_autoscaler_assume_role_policy" {
statement {
actions = ["sts:AssumeRoleWithWebIdentity"]
effect = "Allow"
condition {
test = "StringEquals"
variable = "${replace(aws_iam_openid_connect_provider.eks.url, "https://", "")}:sub"
values = ["system:serviceaccount:kube-system:cluster-autoscaler"]
}
principals {
identifiers = [aws_iam_openid_connect_provider.eks.arn]
type = "Federated"
}
}
}
resource "aws_iam_role" "eks_cluster_autoscaler" {
assume_role_policy = data.aws_iam_policy_document.eks_cluster_autoscaler_assume_role_policy.json
name = "eks-cluster-autoscaler"
}
resource "aws_iam_policy" "eks_cluster_autoscaler" {
name = "eks-cluster-autoscaler"
policy = jsonencode({
Statement = [{
Action = [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeLaunchTemplateVersions"
]
Effect = "Allow"
Resource = "*"
}]
Version = "2012-10-17"
})
}
resource "aws_iam_role_policy_attachment" "eks_cluster_autoscaler_attach" {
role = aws_iam_role.eks_cluster_autoscaler.name
policy_arn = aws_iam_policy.eks_cluster_autoscaler.arn
}
Then we need to deploy the auto-scaler using Helm as shown.
resource "helm_release" "cluster_autoscaler" {
name = "cluster-autoscaler"
chart = "cluster-autoscaler"
repository = "https://kubernetes.github.io/autoscaler"
version = "9.9.2"
namespace = "kube-system"
set {
name = "fullnameOverride"
value = "aws-cluster-autoscaler"
}
set {
name = "autoDiscovery.clusterName"
value = var.cluster_name
}
set {
name = "awsRegion"
value = var.aws_region
}
set {
name = "rbac.serviceAccount.name"
value = "cluster-autoscaler"
}
set {
name = "rbac.serviceAccount.annotations.eks\\.amazonaws\\.com/role-arn"
value = aws_iam_role.eks_cluster_autoscaler.arn
}
depends_on = [
aws_eks_cluster.seitech-cluster,
aws_iam_role.eks_cluster_autoscaler,
aws_iam_policy.eks_cluster_autoscaler,
aws_iam_role_policy_attachment.eks_cluster_autoscaler_attach
]
}
Worker Nodes
The last component related to the EKS infrastructure is defining the attributes for the worker nodes.
We will define the roles and policies for the node groups in order to use them in the subsequent sections.
resource "aws_iam_role" "nodes" {
name = "eks-node-group-nodes"
assume_role_policy = jsonencode({
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
Version = "2012-10-17"
})
}
resource "aws_iam_role_policy_attachment" "nodes-AmazonEKSWorkerNodePolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy"
role = aws_iam_role.nodes.name
}
resource "aws_iam_role_policy_attachment" "nodes-AmazonEKS_CNI_Policy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy"
role = aws_iam_role.nodes.name
}
resource "aws_iam_role_policy_attachment" "nodes-AmazonEC2ContainerRegistryReadOnly" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
role = aws_iam_role.nodes.name
}
Note: All the roles and policies defined in the article are referenced from the AWS documentation and are mandatory for the correct working of the cluster.
After the definition of roles, we need to define the actual node groups. These node groups are divided into two sub-types. The first type is node groups for provisioning on demand EC2 instances. While the second is used in provisioning spot instances. This division is important for decreasing the cluster costs as these spot instances will be used as the Jenkins agents.
resource "aws_eks_node_group" "private-nodes-on-demand" {
cluster_name = aws_eks_cluster.seitech-cluster.name
node_group_name = var.worker_group_name_on_demand
node_role_arn = aws_iam_role.nodes.arn
subnet_ids = [
aws_subnet.private-seitech-subnet1.id,
aws_subnet.private-seitech-subnet2.id,
]
capacity_type = "ON_DEMAND"
instance_types = var.worker_group_instance_type_on_demand
scaling_config {
desired_size = var.autoscaling_group_desired_capacity_on_demand
max_size = var.autoscaling_group_desired_capacity_on_demand
min_size = var.autoscaling_group_desired_capacity_on_demand
}
update_config {
max_unavailable = 1
}
labels = {
Environment = "${var.cluster_name}-dev-on-demand"
instance-type = "on-demand"
}
depends_on = [
aws_iam_role_policy_attachment.nodes-AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.nodes-AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.nodes-AmazonEC2ContainerRegistryReadOnly,
]
}
resource "aws_eks_node_group" "private-nodes-spot" {
cluster_name = aws_eks_cluster.seitech-cluster.name
node_group_name = var.worker_group_name_spot
node_role_arn = aws_iam_role.nodes.arn
subnet_ids = [
aws_subnet.private-seitech-subnet1.id,
aws_subnet.private-seitech-subnet2.id,
]
capacity_type = "SPOT"
instance_types = var.worker_group_instance_type_spot
scaling_config {
desired_size = var.autoscaling_group_desired_capacity_spot
max_size = var.autoscaling_group_max_size_spot
min_size = var.autoscaling_group_min_size_spot
}
update_config {
max_unavailable = 1
}
labels = {
Environment = "${var.cluster_name}-dev-spot"
instance-type = "spot"
}
tags = {
"k8s.io/cluster-autoscaler/${var.cluster_name}" = "owned"
"k8s.io/cluster-autoscaler/enabled" = "TRUE"
"k8s.io/cluster-autoscaler/node-template/label/instance-type" = "spot"
}
depends_on = [
aws_iam_role_policy_attachment.nodes-AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.nodes-AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.nodes-AmazonEC2ContainerRegistryReadOnly,
]
}
Both worker nodes have almost the same attributes and are self-explanatory. We need to emphasize two attributes:
- The tag attribute
- The first attribute is an EKS requirement.
- The second and third are the auto-discovery requirement for the auto-scaler.
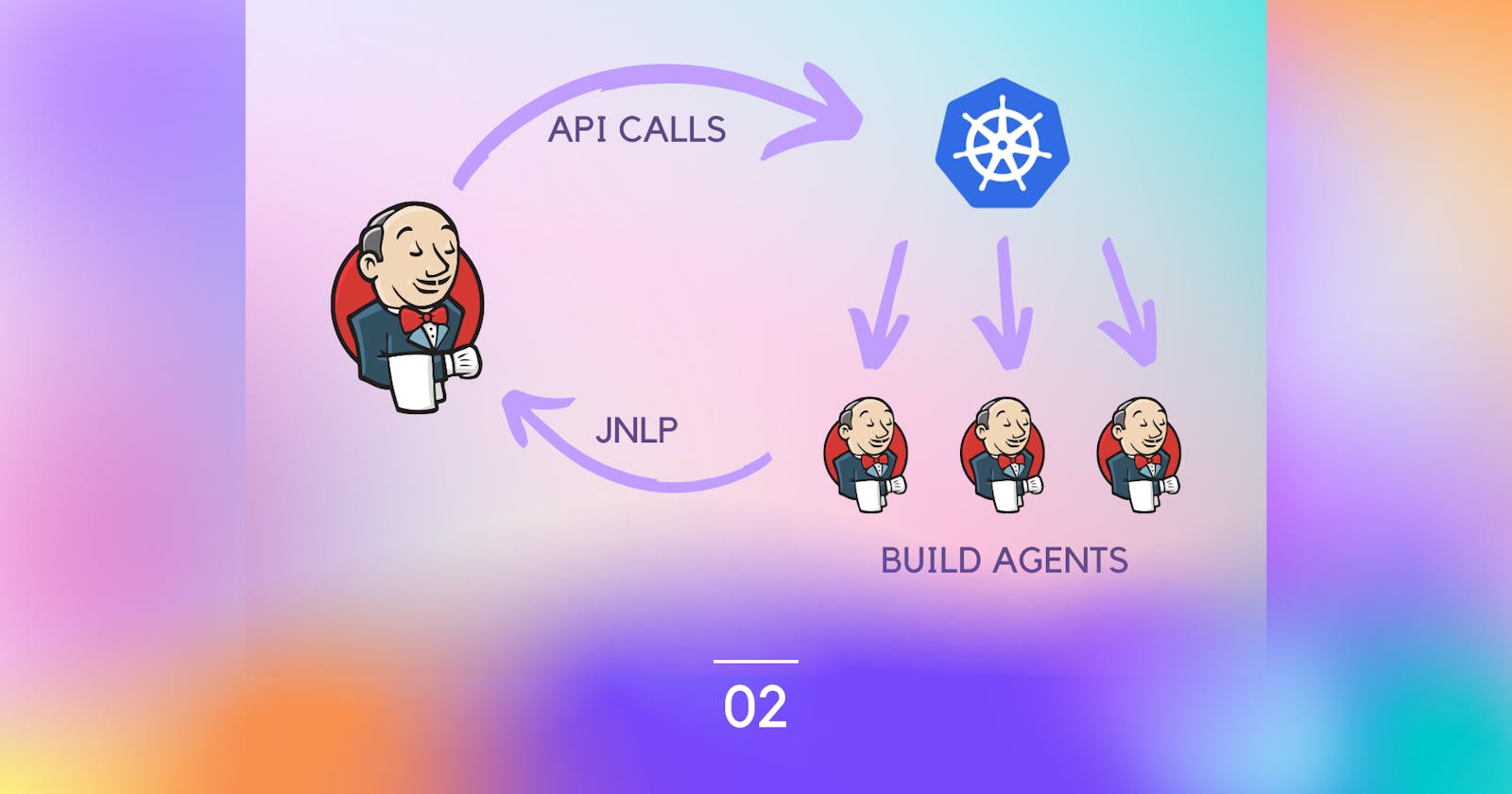
- The labels attribute: it defines instance-type label to use as a nodeSelector in the deployments. We will find later that the first worker group (on_demand) is used as the basic node for the Jenkins controller while the spot nodes will be selected for the agents.
Jenkins Server Configuration
Configuring the Jenkins server without interaction with the UI is one goal of this project. To achieve this we will use the Helm chart and Jenkins Configuration as Code (JCasC).
Let's dig into the Jenkins Values file from top to bottom:
controller:
installPlugins:
....
- configuration-as-code:latest
- kubernetes:latest
- prometheus:latest
....
numExecutors: 1
containerEnv:
- name: JENKINS_GITHUB_USERNAME
valueFrom:
secretKeyRef:
name: jenkins-secrets
key: jenkins-github-username
- name: JENKINS_GITHUB_PASSWORD
valueFrom:
secretKeyRef:
name: jenkins-secrets
key: jenkins-github-password
serviceType: LoadBalancer
adminUser: "admin"
adminPassword: "admin"
nodeSelector:
instance-type: on-demand
The first object in the file is the controller. This object will have some other objects like installPlugins. Let's define each concept separately.
- controller.installPlugins: List of Jenkins plugins to install. Installing "Kubernetes" and "Configuration as Code" is important.
- numExecutors: Number of Jenkins executors.
- containerEnv: Environment variables for Jenkins Container. In our example, environment variables will be deduced from Kubernetes secrets.
- serviceType: k8s service type.
- adminUser: Admin username.
- adminPassword: Admin password.
- nodeSelector: Node labels for pod assignment.
Another important attribute of the Jenkins Controller is the JCasC config:
JCasC:
defaultConfig: true
configScripts:
base-configs: |
jenkins:
systemMessage: "SEITech Demo CI Pipeline"
credentials:
system:
domainCredentials:
- credentials:
- usernamePassword:
scope: GLOBAL
id: "${JENKINS_GITHUB_USERNAME}-github-organization"
username: "${JENKINS_GITHUB_USERNAME}"
password: "${JENKINS_GITHUB_PASSWORD}"
- aws:
scope: GLOBAL
id: "${JENKINS_GITHUB_USERNAME}-aws-creds"
accessKey: "${AWS_ACCESS_KEY}"
secretKey: "${AWS_SECRET_ACCESS_KEY}"
description: "AWS Credentials"
jobs:
- script: >
organizationFolder("${JENKINS_GITHUB_USERNAME}") {
description("Github Organization - ${JENKINS_GITHUB_USERNAME}")
displayName("Organization: ${JENKINS_GITHUB_USERNAME}")
buildStrategies {
skipInitialBuildOnFirstBranchIndexing()
}
organizations {
github {
repoOwner("${JENKINS_GITHUB_USERNAME}")
apiUri("https://api.github.com")
buildForkPRHead(true)
buildForkPRMerge(true)
buildOriginBranch(true)
buildOriginBranchWithPR(true)
buildOriginPRHead(true)
buildOriginPRMerge(true)
credentialsId("${JENKINS_GITHUB_USERNAME}-github-organization")
traits {
gitBranchDiscovery()
gitHubBranchDiscovery {
strategyId(1)
}
sourceWildcardFilter {
includes("seitech*")
excludes("")
}
}
configure { node ->
node / triggers / 'com.cloudbees.hudson.plugins.folder.computed.PeriodicFolderTrigger' {
spec('H H * * *')
interval(86400000)
}
}
}
}
}
JCasC uses Configuration as Code Plugin to inject the Jenkins configurations. In our example, we configure the server to show a custom system message and add some credentials for GitHub access. Finally, we configure a seed job to configure an Organization Folder job to integrate all the organization's repos to the Jenkins server. The Jenkins server will then detect the "Jenkinsfile" in each project and execute the pipeline.
Finally, we will look at the agent object. We just define the nodeSelector to use spot instances.
agent:
nodeSelector:
instance-type: spot
To deploy all these configurations, we will use the helm_release as shown in the following snippet.
resource "helm_release" "jenkins" {
name = "jenkins"
repository = "https://charts.jenkins.io"
chart = "jenkins"
values = [
"${file("jenkins-values.yaml")}"
]
set_sensitive {
name = "controller.adminUser"
value = var.jenkins_admin_username
}
set_sensitive {
name = "controller.adminPassword"
value = var.jenkins_admin_password
}
depends_on = [
aws_eks_cluster.seitech-cluster
]
}
Monitoring Tools
Grafana
Again we will use Helm to deploy Grafana with the following values file.
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards/default
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-server.default.svc.cluster.local
access: proxy
isDefault: true
dashboards:
default:
9964-jenkins-performance-and-health-overview:
gnetId: 9964
revision: 1
datasource: Prometheus
6417-kubernetes-cluster-prometheus:
gnetId: 6417
revision: 1
datasource: Prometheus
service:
enabled: true
type: LoadBalancer
To use helm release for Grafana:
resource "helm_release" "grafana" {
name = "grafana"
chart = "grafana"
repository = "https://grafana.github.io/helm-charts"
version = "6.15.0"
namespace = "default"
set {
name = "adminPassword"
value = "admin"
}
values = [
file("grafana-values.yaml"),
]
depends_on = [
aws_eks_cluster.seitech-cluster,
]
}
Prometheus
Prometheus values file:
extraScrapeConfigs: |
- job_name: 'jenkins'
metrics_path: /prometheus
params:
module: [http_2xx]
tls_config:
insecure_skip_verify: true
static_configs:
- targets:
- jenkins.default.svc.cluster.local:8080
Prometheus helm release:
resource "helm_release" "prometheus" {
name = "prometheus"
chart = "prometheus"
repository = "https://prometheus-community.github.io/helm-charts"
version = "15.0"
namespace = "default"
values = ["${file("prometheus-values.yaml")}"]
set {
name = "adminPassword"
value = "admin"
}
depends_on = [
aws_eks_cluster.seitech-cluster,
]
}
Kubernetes Secrets
The following code shows how to deploy secrets to K8s to use in the Jenkins Configuration file.
resource "kubernetes_secret" "jenkins-secrets" {
metadata {
name = "jenkins-secrets"
}
data = {
jenkins-github-username = var.jenkins_github_username
jenkins-github-password = var.jenkins_github_password
}
type = "Opaque"
immutable = true
}
We have reached the end of the implementation section. In the following sections, we will demo some results and comment on this implementation.
Results
The following video shows the results of this implementation.
Conclusion
In the end, implementing this solution in production is helpful for large teams and projects. However, there are too many services to integrate with your implementation especially artifact manager and security firewalls.
References
1- Online Meetup: Configuration as Code of Jenkins (for Kubernetes): youtu.be/KB7thPsG9VA
2- Terraform Helm EKS Jenkins: github.com/Josh-Tracy/Terraform-Helm-EKS-Je..
3- Jenkins Build agents K8s: devopscube.com/jenkins-build-agents-kuberne..
4- Enter the world of Jenkins Configuration as Code - JCasC: github.com/sharepointoscar/JCasC